基于贝叶斯决策理论的分类方法
朴素贝叶斯是贝叶斯决策理论的一部分,所以在学习朴素贝叶斯之前先了解一下贝叶斯决策理论。
假设我们有一个数据集,由两类数据组成:
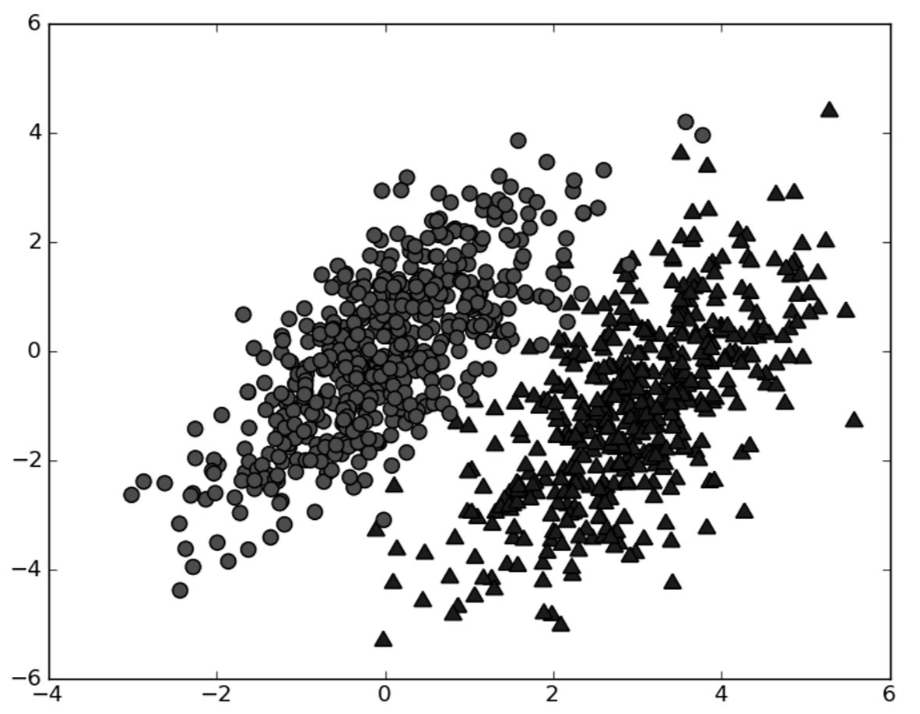
假设已知图中两类数据的统计参数。我们现在用p1(x, y)表示数据点(x, y)属于类别1的概率,用p2(x, y)表示数据点(x, y)数据类别2的概率,那么对于一个新数据点(x, y),可以用下面的规则判断它的类别:
- 如果p1(x, y) > p2(x, y),那么类别为1。
- 如果p2(x, y) > p1(x, y),那么类别为2。
我们会选择高概率对应的类别,这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
但这两个准则并不是贝叶斯决策理论的所有内容,p1()和p2()是为了简化描述,而真正需要比较的是$p(c_1|x, y)$和$p(c_2|x, y)$。这些符号的具体意义是:给定某个由x、y表示的数据点,那么该数据点来自类别$c_1$和$c_2$的概率。
如果已知概率$p(x, y|c_1)$,可以使用贝叶斯准则来交换概率中的条件与结果:
$$
p(c_i|x, y) = \frac{p(x, y|c_i)p(c_i)}{p(x, y)}
$$
使用朴素贝叶斯进行文档分类
朴素贝叶斯的一个假设是样本的特征之间相互独立,即一个特征或者单词出现的可能性与它和其他单词相邻没有关系。当然,这种假设不正确,这个假设正是朴素贝叶斯分类器中朴素的含义。朴素贝叶斯分类器的另一个假设是,每个特征同等重要。其实这个假设也有问题,尽管上述假设存在一些小瑕疵,但朴素贝叶斯的实际效果却很好。
现在我们要维护一个在线社区留言板,为了不影响社区的发展,我们要屏蔽侮辱性言论,对此问题建立两个类别,侮辱类和非侮辱类,使用1和0分别表示。
准备数据:从文本中构建词向量
下面我们将先建立词汇表,然后将每一篇文档转换为词汇表上的向量:
代码清单 bayes.py
1 | def loadDataSet(): |
1 | $ python bayes.py |
训练算法:从词向量计算概率
重写贝叶斯准则,将之前的x、y替换为$\boldsymbol{w}$。$\boldsymbol{w}$表示一个向量,由多个数值组成,这里数值个数即词汇表中的词个数。所要求的概率即为:
$$
p(c_i|\boldsymbol{w}) = \frac{p(\boldsymbol{w}|c_i)p(c_i)}{p(\boldsymbol{w})}
$$
$p(c_i)$可以用类别i的文档数除以总的文档数求得。$p(\boldsymbol{w}|c_i)$的计算就要用到朴素贝叶斯假设了,假设所有词相互独立,将$\boldsymbol{w}$展开为一个个独立特征$p(w_0, w_1, w_2..w_n|c_i)$,它可以使用$p(w_0|c_i)p(w_1|c_i)p(w_2|c_i)…p(w_N|c_i)$来计算。
在bayes.py文件中继续添加代码:
1 | from numpy import * |
1 | $ python bayes.py |
测试算法:根据现实情况修改分类器
要计算多个概率的乘积以获得文档属于某个类别的概率,即计算$p(w_0|1)p(w_1|1)p(w_2|1)…$。如果其中一个概率为0,那么最后的乘积也为0,为消除这种影响,将所有词的出现数初始化为1,并将分母初始化为2。
修改bayes.py中trainNB0():
1 | p0Num = ones(numWords); p1Num = ones(numWords) |
另一个遇到的问题是下溢,这是由于太多很小的数相乘造成的。当计算乘积$p(w_0|c_i)p(w_1|c_i)p(w_2|c_i)…p(w_N|c_i)$时,由于大部分因子都非常小,所以程序会下溢,一种解决办法是对乘积取自然对数。在代数中有$ln(a*b) = ln(a)+ln(b)$,修改return前的两行代码:
1 | p1Vect = log(p1Num/p1Denom) |
下面将分类函数添加到bayes.py中:
1 | def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): |
1 | $ python bayes.py |
条件概率
$$
P(A|B) = \frac{P(AB)}{P(B)}
$$
贝叶斯准则
$$
p(c|x) = \frac{p(x|c)p(c)}{p(x)}
$$
reference
《机器学习实战》