说是移植AFL,其实是移植android-afl,因为AFL的插桩代码都是汇编写的,原版都是ATT汇编,要直接写ARM汇编有点难度,android-afl里有这部分内容,所以改起来容易一些。但是Android和普通Linux还是有一些区别的,我用的是树莓派3B,Raspberry系统。
Ubuntu读取开发板串口数据
我的stm32l431开发板使用的是CH340 USB转串口芯片,Linux默认有这个驱动程序,将设备插到电脑上后在/dev目录下会多一个ttyUSB0设备,用dmesg查看驱动内核log:
1 | $ dmesg |
JTAG调试STM32开发板
JTAG(Joint Test Action Group;联合测试工作组)是一种国际标准测试协议(IEEE 1149.1兼容),主要用于芯片内部测试。现在多数的高级器件都支持JTAG协议,如DSP、FPGA器件等。标准的JTAG接口是4线:TMS、TCK、TDI、TDO,分别为模式选择、时钟、数据输入和数据输出线。
OpenOCD是一个用于JTAG调试的软件, 可以用于不同调试器和CPU, 还可以与GDB配合,stlink和jlink都是符合JTAG标准的调试器。
想在Ubuntu下对stm32开发板进行调试需要先安装OpenOCD下载地址,在Ubuntu16.04上:
DeepSpeech2使用
原项目
下载models v1.11
因为项目要用到official包里的文件,所以将下载的models压缩包解压后,把其中的official文件夹拷贝到python包路径下,比如:
1 | ~/.virtualenvs/deepspeech/lib/python3.5/site-packages |
安装official依赖:
1 | $ pip install -r official/requirements.txt |
Syzkaller原理和源码分析
syzkaller运行流程结构如下图所示,红色标签表示需要配置的选项: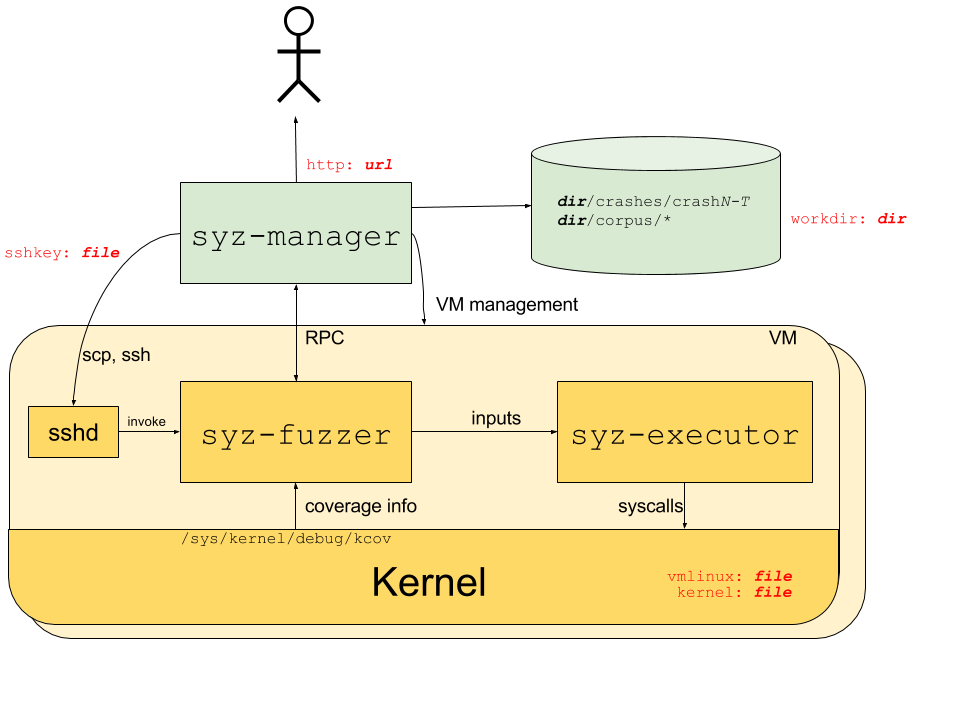
syz-manager用来启动、监控、和重启多个虚拟机实例,并在虚拟机里启动一个syz-fuzzer进程。它负责持久化corpus和存储crash。
Ubuntu下SSH登录Qemu虚拟机
Syzkaller安装 Fuzz Qemu amd64 Kernel
syzkaller官网上有介绍如何在Ubuntu宿主机上用qemu方法fuzz x86_64的Linux内核,但是步骤很分散,在好几个页面上,而且还可能有一些坑,后面会讲到。
首先介绍一下我的环境:
- Ubuntu 16.04 x86_64
- gcc 8.2.0
- linux-5.1
- go1.12.5
用Tensorflow Serving部署自己的模型
Google为了解决机器学习模型部署上线至生产环境,发布了Tensorflow Serving。本文主要通过部署一个手写数字识别的模型来介绍Tensorflow Serving的基本用法。