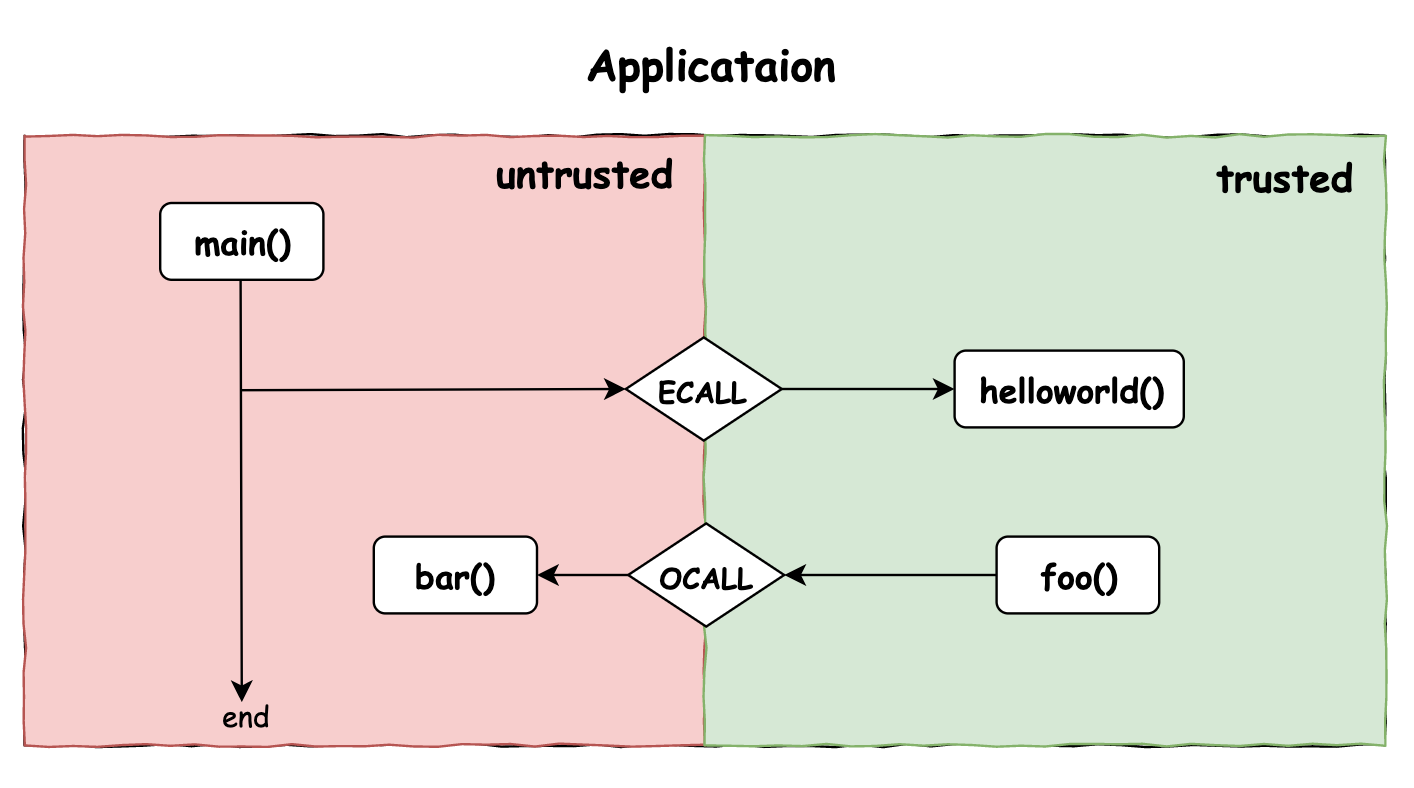
Occlum入门
Occlum是一款蚂蚁集团开源的LibOS,目的是为了降低SGX应用开发门槛。传统的SGX开发存在一定的开发困境:
1.需要将应用程序分为两部分,可信部分和不可信部分。
2.可以使用的编程语言受限制。
3.功能受限制,Enclave无法访问不可信OS,是不可信环境的一个很小的功能子集。
Occlum解决了上述问题,实现了类似docker的命令,使得正常开发的程序可以在SGX可信环境中运行。
git仓库地址:https://github.com/cilium/ebpf
我的环境:Ubuntu 20.04 64bit
好长时间没有更新博客了,其实工作中也会写一些技术文档,但是工作内容相关的文档不能公开,自己也会学一些工作之外的技术,但是形成的文档感觉比较零散,也懒得发布到博客上。感觉还是要多写一些东西记录一下学习的知识和心得,要不总有一种知识不是自己的感觉,也不容易深入学习,形成体系。
其实之前的Android linker文章中有提到,但是没有实际写过时间长了就忘记了。so文件是一个elf格式的文件,在so被加载之前,会执行init段的代码。在结束的时候,会执行fini段的代码。这个技术一般是用来解密加壳文件的,我遇到的场景是加沙箱,下面就介绍一下实现方法。
PID namespace用来隔离进程的PID空间,使得不同PID namespace中的进程号可以重复且互不影响。Linux下的每个进程都有一个对应的/proc/pid目录,该目录包含了进程相关的信息。对于一个PID namespace,/proc目录只包含当前namespace和它所有子孙后代namespace里的进程信息。创建一个新的PID namespace后,需要挂载/proc文件系统才能让子进程中top、ps等依赖/proc文件系统的命令正常工作。
mount namespace稍微简单点,因为PID namesapce需要用到所以就先简单介绍一下。
mount namespace是用来隔离文件系统的挂载点,这样进程就只能看到自己的文件系统挂载点。新mount namespace中的挂载点是从调用者所在的mount namespace中拷贝的,但是新mount namespace创建后和原mount namespace就没啥关系了(除了shared subtree的情况),下面通过iso文件的挂载来演示。
接下来打算逐个学习一下Linux namespace的作用和用法,顺序不一定科学,随心随性学习法。。第一个学的是User namespace,先学这个是因为在看Chrome沙箱的时候,用到的就是User namespace。
1.命令行使用
通过unshare命令可以启动所有的7种namespace,启动user namespace:
unionFS可以把文件系统上的多个目录内容联合挂载到同一个目录下,而目录的物理位置是分开的。先用一个简单的例子体会一下:
1.先创建如下的目录结构